CSV Tool
Disclaimer
Your use of this download is governed by Stonebranch’s Terms of Use, which are available at https://www.stonebranch.com/integration-hub/Terms-and-Privacy/Terms-of-Use/.
Version Information
| Template Name | Extension Name | Extension Version |
|---|---|---|
| ue-csv-tool | CSV Tool | 1.0.0 |
Refer to Changelog for version history information.
Overview
This Universal Extension is a tool to process input data in Comma-Separated Value (CSV), Delimited Separated Value (DSV), or Tab Separated Value (TSV) formats. It is typically used when input data need to be read, filtered, and possibly saved into new files or transformed into JSON format.
Key Features
| Feature | Description |
|---|---|
| Read, Filter, Save and Transform CSV data | Read Input CSV/DSV/TSV input files with the capability to perform row filtering and
|
| Support for multiple data formats | Universal Task enables users to select well-known input data formats (known also as dialects) to parse and process Input data. The dialect list is the following:
A “Custom” option also exists to provide full flexibility. |
Requirements
This integration requires a Universal Agent and a Python runtime to execute the Universal Task.
| Area | Details |
|---|---|
| Python Version | Requires Python of version 3.7. Tested with the Universal Agent bundled Python distribution (python version 3.7.6). |
| Universal Agent | Both Windows and Linux agents are supported:
|
| Universal Controller | Universal Controller Version >= 7.1.0.0 |
Supported Actions
Action: Process CSV/DSV/TSV File
Read Input CSV/DSV/TSV input files with the capability to perform row filtering and:
Save data on a new file of the same format
Transform Data into JSON (as EXTENSION Output)
Row Filtering is performed against the values of a specific column. For more information refer to Extension Parameter and Fields.
Configuration examples
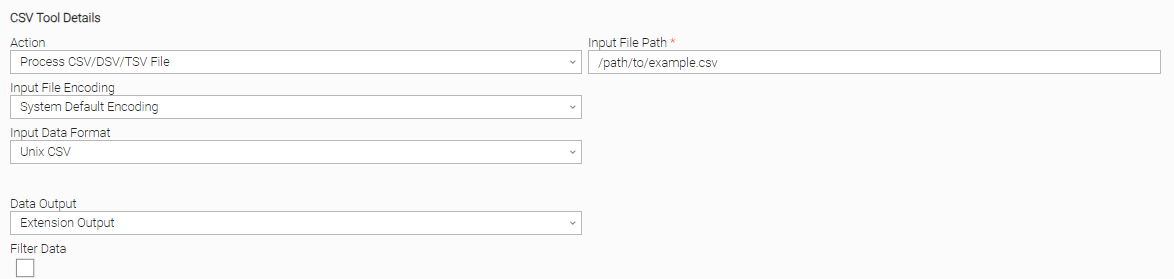
User Scenario: Process a CSV file by selecting the UNIX CSV input data format, and using the system's default encoding.
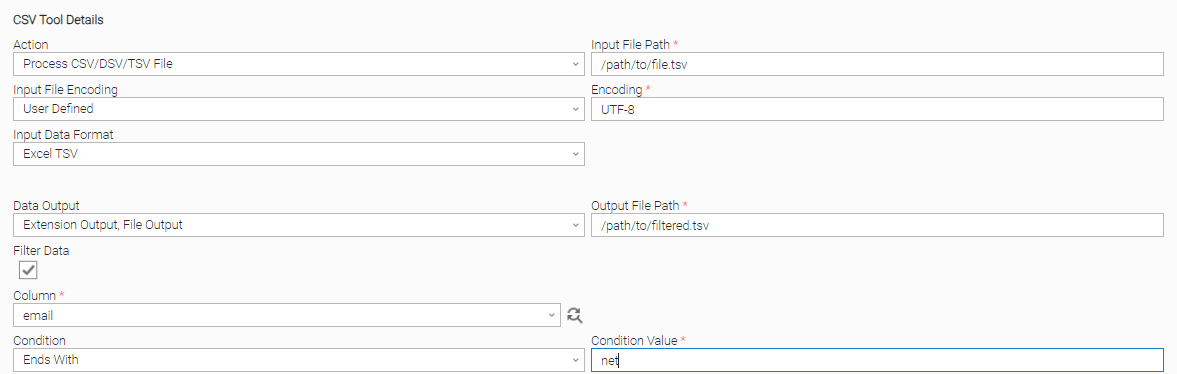
User Scenario: Process a TSV (Excel TSV file format), filter rows based on column data, save the data on a new CSV file, and send data on Extension Output (JSON format).
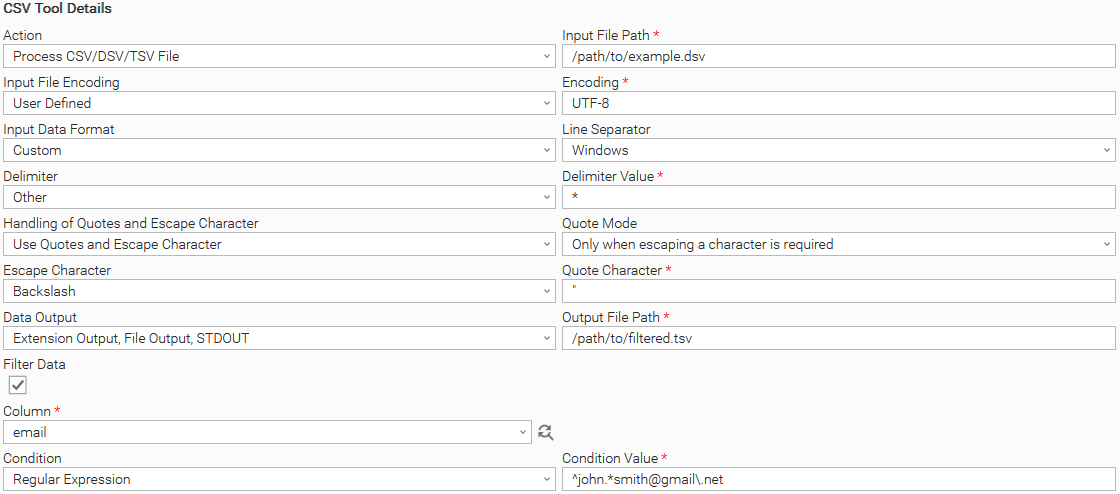
User Scenario: Process a DSV file by providing additional parsing details through the “Custom“ Input Data Format option., filter rows based on column data with a regex, save the data on a new DSV file, and send data on Extension Output (JSON format).
Action Output
Output Type | Description (Successful Execution) | Example (Successful Execution) |
|---|---|---|
EXTENSION | The extension output follows the standard Extension Output format, providing:
| |
Description (Failed Execution) | Example (Failed Execution) | |
The extension output follows the standard Extension Output format, providing:
| | |
STDOUT | The CSV, DSV, or TSV data are printed in human-friendly tabular format for visibility purposes (e.g. when filtering is applied and the user tests the task before saving it in production). | |
Extension Parameters & Fields
Field | Type | Default Value | Required | Description | Introduced in Version |
|---|---|---|---|---|---|
Action | Choice | Process CSV, DSV or TSV File | Yes | The action performed upon the task execution. Available actions are as follows:
| 1.0.0 |
Input File Path | Text | Yes | The path to the input file that is to be processed. | 1.0.0 | |
Input File Encoding | Choice | System Default Encoding | Yes | The mode for selection of Input File Encoding. Two modes are available
When “System Default Encoding” is selected the default Operating System encoding is used. | 1.0.0 |
Encoding | Text | Optional | The encoding used by the input file. Supported encodings can be found in the official 3.7 python documentation. Available when Input File Encoding = “User Defined” | 1.0.0 | |
Input Data Format | Choice | Excel CSV | Yes | The input data format. There are some ready-to-use formats (also known as dialects) as well as a “Custom” option which provides full flexibility.
| 1.0.0 |
Delimiter | Choice | Comma | Yes | The character to be used as delimiter when processing input data. Available delimiters are as follows:
Available when Input Data Format = “Custom” | 1.0.0 |
Delimiter Value | Text | Optional | The specified value of the delimiter. Available when Input Data Format = “Custom” and Delimiter = “Other” | 1.0.0 | |
Line Separator | Choice | Windows (\r\n) | Yes | The character to be used as record separator. Available record separators are as follows:
Available when Input Data Format = “Custom” | 1.0.0 |
Handling of Quotes and Escape Character | Choice | Use only Quotes | Yes | The strategy used by the input file to escape special characters present in value fields such as a delimiter, CR, LF, etc. Available escape strategies are as follows:
Available when Input Data Format = “Custom” | 1.0.0 |
Quote Mode | Choice | Only when escaping a character is required | Optional | The quote mode used by the input file. Available quote modes are as follows:
Available when Input Data Format = “Custom” and Handling of Quotes and Escape Character is either “Use only Quotes” or “Use Quotes and Escape Character” | 1.0.0 |
Escape Character | Choice | Double Quote | Optional | The character to be used as escape character. Available when Input Data Format = “Custom” & Handling of Quotes and Escape Character is either “Use only Escape Character” or “Use Quotes and Escape Character”. Available escape characters are as follows:
| 1.0.0 |
Quote Character | Text | “ | Optional | The character to be used as quote character when processing the input data. Available when Input Data Format = “Custom” and Handling of Quotes and Escape Character is either “Use only Quotes” or “Use Quotes and Escape Character” | 1.0.0 |
Data Output | Multiple Choice | Extension Output | Yes | The data output method. Available actions are as follows:
| 1.0.0 |
Output File Path | Text | Optional | The path to the output file where filtered data are to be stored. Output file format is the same as the Input File format. If the file already exists it is overwritten. | 1.0.0 | |
Filter Data | Boolean | false | Yes | Enables data filtering and unfolds on the UI the available filter options | 1.0.0 |
Column | Dynamic Choice | Optional | The column’s name based on which to apply the filtering. The first row of input data is always presumed to be the headers row (the row that represents the column names) Available only when Filter Data = True | 1.0.0 | |
Condition | Choice | Equals | Optional | Determines the row filtering condition that will be used to filter the rows of data. Available filtering conditions are as follows:
Available only when Filter Data = True | 1.0.0 |
Condition Value | Text | Optional | The condition’s value. Available only when Filter Data = True | 1.0.0 |
Extension Cancellation
When a “cancel command” is received from the controller, any temporary file is cleaned up and everything returns to the state that it was before the task was run.
Extension Exit Codes
Extension Exit Code | Status | Status Description | Meaning |
|---|---|---|---|
0 | SUCCESS | “SUCCESS: Task executed successfully. <<Additional Information>>“ | Successful Execution |
1 | FAIL | “FAIL: <<Error Description>>” | This error is mapped to the following cases:
|
20 | DATA_VALIDATION_ERROR | “DATA_VALIDATION_ERROR: <<Error Description>>“ ** See STDERR for more detailed error descriptions. | Input fields validation error. See STDERR for more detailed error descriptions. |
21 | INPUT_FILE_NOT_FOUND_ERROR | “INPUT_FILE_NOT_FOUND_ERROR: Input file could not be found.” | The path specified in the “Input File Path“ field is not valid. |
22 | OUTPUT_FILE_PATH_ERROR | “OUTPUT_FILE_PATH_ERROR: The following file path is not valid: <<Filepath>>.” | The path specified in the “Output File Path“ field is not valid. |
23 | FILE_FORMAT_ERROR | “FILE_FORMAT_ERROR: The format of the input file does not match the specified format.“ | The format of the input file is not the same as the one specified in the input fields. |
24 | HEADER_ROW_NOT_FOUND_ERROR | “HEADER_ROW_NOT_FOUND_ERROR: Input file does not contain a header row.“ | The input file does not contain a header row. |
25 | INVALID_COLUMN_ERROR | “INVALID_COLUMN_ERROR: Specified column does not exist.“ | The column specified in the “Column“ field does not exist. |
50 | PERMISSION_ERROR | “PERMISSION_ERROR: <<Error Description>>“ | Failed to access or write to file. |
STDOUT and STDERR
STDOUT and STDERR provide additional information to User. The populated content can be changed in future versions of this extension without notice. Backward compatibility is not guaranteed.
How To
Import Universal Template
To use the Universal Template, you first must perform the following steps.
This Universal Task requires the Resolvable Credentials feature. Check that the Resolvable Credentials Permitted system property has been set to true.
To import the Universal Template into your Controller, follow these instructions.
When the files have been imported successfully, refresh the Universal Templates list; the Universal Template will appear on the list.
Modifications of this integration, applied by users or customers, before or after import, might affect the supportability of this integration. For more information refer to Integration Modifications.
Configure Universal Task
For a new Universal Task, create a new task, and enter the required input fields.
Environment Variables
For performance and memory tuning the extension recognizes two environment variables.
UE_INPUT_FILE_BUFFER_LINESexpects an integer value and controls how many lines are read at a time from the input file and written to the output file (if one is provided). Higher numbers for this variable will increase performance but may also significantly increase the memory usage of the extension. Lower numbers reduce memory usage but may also reduce performance. A default value of 1000 is used if none is provided and considered most suitable for the majority of the cases.UE_EXTENSION_OUTPUT_MAX_LINESexpects an integer value and controls the maximum number of rows from the input file that is printed as JSON on the Extension output. If the number of rows of the input file exceeds the value provided to this variable the number of rows is truncated to the value of this variable and the message “Extension output, maximum number of lines reached.” is appended to the Status Description of the task. This truncation only affects data printed to the Extension Output and does not affect the rest of the outputs (STDOUT, File Output).
Integration Modifications
Modifications applied by users or customers, before or after import, might affect the supportability of this integration. The following modifications are discouraged to retain the support level as applied for this integration.
Python code modifications should not be done.
Template Modifications
General Section
"Name", "Extension", "Variable Prefix", and "Icon" should not be changed.
Universal Template Details Section
"Template Type", "Agent Type", "Send Extension Variables", and "Always Cancel on Force Finish" should not be changed.
Result Processing Defaults Section
Success and Failure Exit codes should not be changed.
Success and Failure Output processing should not be changed.
Fields Restriction Section
The setup of the template does not impose any restrictions. However, with respect to the "Exit Code Processing Fields" section.Success/Failure exit codes need to be respected.
In principle, as STDERR and STDOUT outputs can change in follow-up releases of this integration, they should not be considered reliable sources for determining the success or failure of a task.
Users and customers are encouraged to report defects, or feature requests at Stonebranch Support Desk.
Use Cases
Using the extension with a Recurring Task.
The extension can be used with a recurring task to execute tasks based on CSV input where each file row represents the input for a task.
Suppose we have a list of contacts stored in a CSV and we want to email every contact related to the Ferrell LLC company.
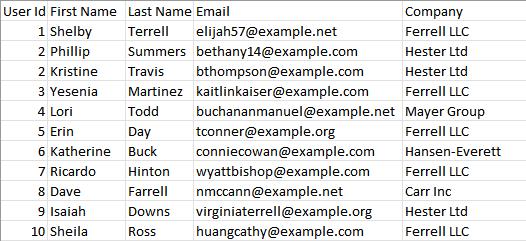
This can be done with a recurring task. In each iteration, the recurring task takes a file row as input and sends the corresponding email. In the first iteration, the recurrent task takes the first row of the file as input, in the second iteration it takes the second row as input, etc.
Firstly, we create a workflow and add two tasks to it.
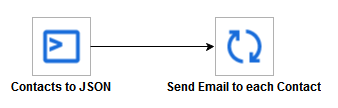
The first is a CSV Tool task that takes the contacts file as input, filters it based on the company, and converts it to JSON.
.png?version=1&modificationDate=1691157797281&cacheVersion=1&api=v2&width=805&height=249)
The second one is a recurrent task that sends an email to each contact in the file.
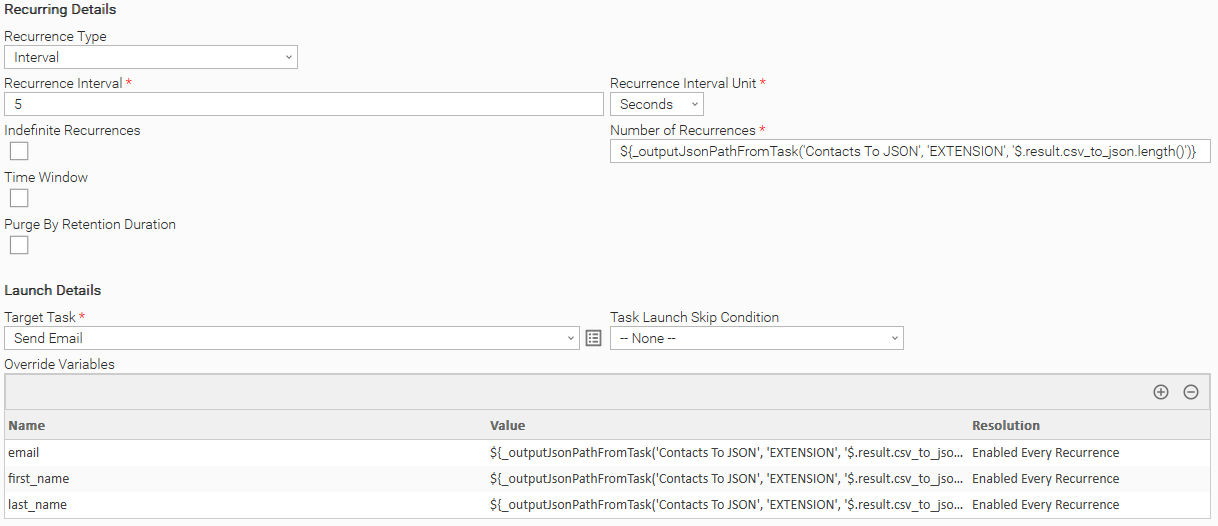
Using the following command, we set the number of recurrences to be equal to the number of file rows.
${_outputJsonPathFromTask('Contacts To JSON', 'EXTENSION', '$.result.csv_to_json.length()')}
From 7.4 onward we can use ${__varCsvRecordCount('mapping_csv')} to get the length of a CSV file, where mapping_csv is a variable that holds the CSV data.
Using the following command, we extract the field value from each row where "field" stands for the field's header name.
${_outputJsonPathFromTask('Contacts To JSON', 'EXTENSION', '$.result.csv_to_json.[${__subtract('${ops_recurrence_count}','1')}].field')}
From 7.4 onward ${ops_recurrence_count_minus_1} can be used instead of ${__subtract('${ops_recurrence_count}','1').
${_varCsvRecordValue('mapping_csv', ${ops_recurrence_count_minus_1}, 0)} can be used to get a field value from a CSV file.
Usage Principles
When filtered data is large then the optimal way is to use a file as output, without pushing the data as Extension Output.
When filtered data needs to be easily visible in a workflow and it's small in size then you can consider having it as Extension Output (JSON format)
However, task authors should be aware that having the data as Extension Output means it is stored in the UC database.
As a general principle, storing data in the UC database that are not necessary should be avoided and that has certain benefits towards performance and storage capacity.
Document References
This document references the following documents:
Document Link | Description |
|---|---|
User documentation for creating, working with and understanding Universal Templates and Integrations. | |
User documentation for creating Universal Tasks in the Universal Controller user interface. |
Changelog
ue-csv-tool-1.0.0 (08-04-2023)
Initial Version